


Balkendiagramme für Mittelwerte
Im Rahmen der Blogparade von SAS zum Thema Datenvisualisierung gibt Betram Schäfer (CEO der Firma Statcon) Hinweise zur Verwendung von Balkendiagrammen.
Sehr oft werden in einem Balkendiagramm Mittelwerte von Daten einer Gruppe auf der Ordinate (Y-Achse) abgebildet, dabei sollten einige Besonderheiten beachtet werden. Beispielhaft sollen die unten dargestellten, erfundenen Daten eines Backexperimentes verwendet werden:

Beschreibung des Experimentes:
Es handelt sich um Daten eines faktoriellen Versuchsplans, bei welchem zwei unterschiedliche Mehlqualitäten (billig - teuer) bei zwei Backzeiten (kurz-lang) verarbeitet wurden. Alle anderen Komponenten des Rezeptes (Mehlanteil, Wasseranteil, Backtemperatur, ...) blieben unverändert.
Gemessen wurde der Geschmack anhand einer Gruppe von Testpersonen. Jede Testperson sollte das Brot auf einer Skala von 0 (schmeckt nicht) bis 100 (schmeckt hervorragend) bewerten. Im Datensatz werden die durchschnittlichen Bewertungen der unterschiedlichen Probanden für jedes Brot dargestellt.
Außerdem wurde die Härte der Kruste ermittelt. Das passiert indem die Kraft eines Dornes gemessen wurde, die benötigt wird um durch die Kruste zu brechen. Aus diesen Daten können leicht folgende Mittelwerte und Streuungen ermittelt werden:

Ein möglicher Weg die Daten zu visualisieren wäre der Folgende:
 |
| Balkeniagramm (JMP10 Pro) |
Während das Balkendiagramm für die Kruste sinn macht ist es eher fraglich, ob wie ein vergleichbares Balkendiagramm auch für den Geschmack anwenden sollten. Gehen wir von folgendem Diagramm aus:
 |
| Balkendiagramm für Daten ohne sinnvollen Nullpunkt (ggplot2/R) |
Scheinbar gibt es im Geschmack keinen wirklichen Unterschied zwischen den vier Gruppen. Alle Gruppen scheinen eine Bewertung von etwa 70 Punkten zu bekommen. Der Balken referenziert jetzt allerdings auf den Null-Punkt als Basis, also als schlechtest mögliche Wertung. Ist dieser Ausgangspunkt sinnvoll?
Es stellt sich doch die Frage: Kann es überhaupt ein schlechtestes Brot geben? Gibt es ein Brot mit einem Geschmack von 0 Punkten?
Zwar haben wir bei der Bewertung des Geschmacks willkürliche Grenzen vorgegeben, doch ist kein wirkliches technisch, sinnvolles Maximum oder Minimum für die Bewertung des Geschmacks erkennbar. Es ist also ohne weiteres denkbar die Y-Skala des Balkendiagrammes anzupassen. Eine vernünftige Basis könnte ja überall sein, nicht zwangsläufig an der 0.
 |
| Balkendiagramm mit willkürlicher Y-Achse (ggplot2/R) |
Wie man sieht hängt das Erscheinungsbild des Diagramms dramatisch von der Wahl der Y-Achsen-Skala ab. Nimmt man die Basis 0 scheint es keine Unterschiede zwischen den Gruppen zu geben, wählt man statt dessen eine Basis von 67 bemerkt man, dass es dramatische Unterschiede zwischen billig*kurz und billig*lang zu geben scheint.
Wenn eine Grafik so stark von einer willkürlich getroffenen Entscheidung abhängt kann sie nicht zu einer objektiven Datenanalyse geeignet sein.
Alternative: Streudiagramm mit Fehlerbalken
Die Streudiagramme stellen im Gegensatz zu Balkendiagrammen keine explizite Verbindung zu einem Nullpunkt her!
 |
| Scatterplot mit Mittelwerten und Fehlerbalken (ggplot2/R) |
Dieses Diagramm beinhaltet drei Komponenten:
- Die tatsächlichen Beobachtungen (schwarze Punkte)
- Die Gruppenmittelwerte (weiße Punkte)
- Die zu den Gruppenmittelwerten gehörigen Fehlerbalken.
Wenn man die Mittelwerte von Gruppen vergleichen möchte sind Fehlerbalken ein Hilfsmittel um die Streuung der Daten mit zu Berücksichtigen. Fehlerbalken sind vertikale Linien, die ausgehend vom Mittelwert nach oben und unten unterschiedliche Längen haben können, meist aber symmetrisch sind. Die Symmetrie hängt von der Verteilung der Daten ab, die Länge der Fehlerbalken vom gewählten Kennwert.
Für verschiedene Fragestellungen kommen unterschiedliche Fehlerbalken in Frage.
| Fragestellung | Fehlerbalken |
|---|---|
| Beschreibung der Verteilung der Daten (ohne Annahmen) |
Minimum, Maximum |
| Beschreibung der Verteilung der Daten (ohne Annahmen) |
5%- und 95%-Percentil |
| Beschreibung der Verteilung der Daten (Annahme: Symmetrische Verteilung) |
Standardabweichung |
| Beschreibung der Verteilung der Mittelwerte (Annahme: Symmetrische Verteilung) |
Standardfehler |
| Beschreibung der Verteilung zweier Mittelwerte (Zentraler Grenzwertsatz) |
Konfidenzintervalle(95% oder 99%) |
| Induktion über mehrere Mittelwerte | korrigierte Konfidenzintervalle (z.B. Bonferroni) |
| Induktion über mehrere Mittelwerte - Varianzanalyse (Annahmen: gleiche Streuung in den Gruppen Normalverteilte Residuen) | Konfidenzintervalle mit gepoolter Streuung |
Induktion meint hier, das von der Daten einer Stichprobe ein Schlussfolgerung über die Grundgesamtheit abgeleitet wird. Z.B. weil sich die dargestellten Daten so deutlich unterschiedlich darstellen, wird entschieden das in Zukunft nur noch der bessere Mehltyp verwendet wird. Die alternative Entscheidung wäre würde für dieses Beispiel lauten: Weil sich die Mehltypen nur geringfügig unterscheiden können auch in Zukunft beide Mehlttypen verwendet werden.
Für diese Art der Schlüsse, die auf der Basis von Daten abgeleitet werden gelten besondere Regeln, die auch die Art der Fehlerbalken bestimmen.
Die meisten Balkendiagramme für Mittelwerte, auch wenn Sie Fehlerbalken enthalten definieren die Fehlerbalken nicht, obwohl diese abgebildet werden. Offensichtlich gehen die Ersteller davon aus, dass es nur eine sinnvolle Art von Fehlerbalken gibt. Ohne eine deutliche Angabe über die Art des gewählten Fehlerbalkens ist dieser nicht interpretierbar und daher sinnlos!
 |
| Übersicht über verschiedene Fehlerbalken (ggplot2/R - Klicken zum Vergrößern) |
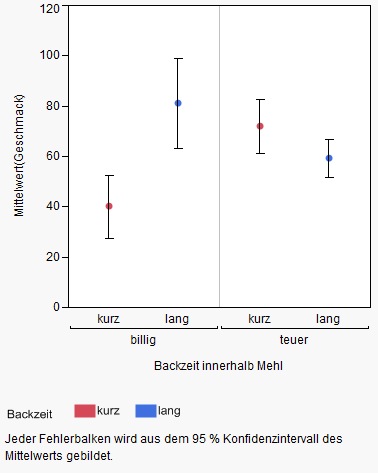 |
| Mittelwerte mit Fehlerbalken (Konfidenzintervall 95% - JMP10 Pro) |
Werden im Rahmen der Interpretation induktive Schlüsse gezogen, wie z.B. das sich die beiden Mehltypen im mittleren Geschmack unterscheiden, so muss der Fehlerbalken mindestens ein Konfidenzintervall abbilden, um diesen Schluss graphisch zu untermauern.
Ausblick
In einem weiteren Eintrag werden wir auf spezielle Graphen zur Visualisierung von Effekten in verschiedenen Studientypen eingehen. Das beinhaltet die Visualisierung in Mixed Models.
Autor: Bertram Schaefer